VRF Lite for fun and profit / Sandbox / Habr
Технология Virtual Routing and Forwarding (VRF) нашла широкое применение в сетях MPLS. В таких сетях метки MPLS применяются для разграничения трафика различных пользователей, а VRF поддерживает таблицу маршрутизации для каждого из них. Для обмена маршрутной информацией в таких сетях применяется MP-BGP.Но существует возможность использовать технологию VRF без MPLS — VRF Lite.
VRF Lite
Рассмотрим топологию, изображенную на первом рисунке. Предположим, к маршрутизатору R1 подключены четыре сети. Необходимо разграничить взаимодействие между сетями так, чтобы первая имела связь со второй, третья с четвертой, но между первой и третьей, первой и четвертой, второй и третьей, второй и четвертой связи не было. Одним из возможных решений будет применение списков доступа (ACL). Второй путь — разделить сети с помощью VRF. Ниже приведена конфигурация, позволяющая это сделать.
!включаем маршрутизацию
ip routing
!включаем Cisco Express Forwarding, необходимый для работы VRF
ip cef
!объявляем два VRF с именами ONE и TWO
ip vrf ONE
!указываем route-distinguisher
rd 65000:1
ip vrf TWO
rd 65000:2
interface FastEthernet 0/0
!указываем, что интерфейс относится к тому или иному VRF
!это необходимо сделать до указания IP адреса
!так как команда ip vrf forwarding удаляет адрес с интерфейса
ip address 10.0.1.1 255.255.255.0
no shutdown
interface FastEthernet 0/1
ip vrf forwarding ONE
ip address 10.0.2.1 255.255.255.0
no shutdown
interface FastEthernet 1/0
ip vrf forwarding TWO
ip address 10.0.3.1 255.255.255.0
no shutdown
interface FastEthernet 1/1
ip vrf forwarding TWO
ip address 10.0.4.1 255.255.255.0
no shutdown
Route-distinguisher (RD) — уникальное число, хранящееся рядом с каждым маршрутом в таблице маршрутизации для различения, к какому VRF какой маршрут принадлежит. RD может быть записан в одном из двух форматов: :<число> или <IP адрес>:<число>, где <число> — десятичное число. При использовании VRF Lite RD не так важно, как в полноценных сетях MPLS+VRF, потому единственное требование, чтобы его значение было уникальным в рамках одного маршрутизатора.
Теперь можно посмотреть, что у нас получилось:
Интерфейсы маршрутизатора и их сопоставление с VRF.
R1#show ip interface brief
Interface IP-Address OK? Method Status Protocol
FastEthernet0/0 10.0.1.1 YES manual up up
FastEthernet0/1 10.0.2.1 YES manual up up
FastEthernet1/0 10.0.3.1 YES manual up up
FastEthernet1/1 10.0.4.1 YES manual up up
R1#show ip vrf
Name Default RD Interfaces
ONE 65000:1 Fa0/0
Fa0/1
TWO 65000:2 Fa1/0
Fa1/1
Таблицы маршрутизации глобальная и для каждого VRF
R1#show ip route
…
Gateway of last resort is not set
R1#show ip route vrf ONE
Routing Table: ONE
…
Gateway of last resort is not set
10.0.0.0/24 is subnetted, 2 subnets
C 10.0.2.0 is directly connected, FastEthernet0/1
C 10.0.1.0 is directly connected, FastEthernet0/0
R1#show ip route vrf TWO
Routing Table: TWO
…
Gateway of last resort is not set
10.0.0.0/24 is subnetted, 2 subnets
C 10.0.3.0 is directly connected, FastEthernet1/0
C 10.0.4.0 is directly connected, FastEthernet1/1
Проверим связь между сетями:
R1#ping vrf ONE 10.0.1.1
Type escape sequence to abort.
Sending 5, 100-byte ICMP Echos to 10.0.1.1, timeout is 2 seconds:
!!!!!
Success rate is 100 percent (5/5), round-trip min/avg/max = 1/2/4 ms
R1#ping vrf ONE 10.0.2.1
Type escape sequence to abort.
Sending 5, 100-byte ICMP Echos to 10.0.2.1, timeout is 2 seconds:
!!!!!
Success rate is 100 percent (5/5), round-trip min/avg/max = 1/1/1 ms
R1#ping vrf ONE 10.0.3.1
Type escape sequence to abort.
Sending 5, 100-byte ICMP Echos to 10.0.3.1, timeout is 2 seconds:
…..
Success rate is 0 percent (0/5)
R1#ping vrf ONE 10.0.4.1
Sending 5, 100-byte ICMP Echos to 10.0.4.1, timeout is 2 seconds:
…..
Success rate is 0 percent (0/5)
R1#ping vrf TWO 10.0.1.1
Type escape sequence to abort.
Sending 5, 100-byte ICMP Echos to 10.0.1.1, timeout is 2 seconds:
…..
Success rate is 0 percent (0/5)
R1#ping vrf TWO 10.0.2.1
Type escape sequence to abort.
Sending 5, 100-byte ICMP Echos to 10.0.2.1, timeout is 2 seconds:
…..
Success rate is 0 percent (0/5)
R1#ping vrf TWO 10.0.3.1
Type escape sequence to abort.
Sending 5, 100-byte ICMP Echos to 10.0.3.1, timeout is 2 seconds:
!!!!!
Success rate is 100 percent (5/5), round-trip min/avg/max = 1/1/4 ms
R1#ping vrf TWO 10.0.4.1
Type escape sequence to abort.
Sending 5, 100-byte ICMP Echos to 10.0.4.1, timeout is 2 seconds:
!!!!!
Для того, чтобы посмотреть arp таблицу отдельного VRF используйте команду
show ip arp vrf NAME
где NAME — имя VRF.
Кроме того, чтобы установить telnet подключение из определенного VRF необходимо выполнить следующую команду:
telnet HOST /vrf NAME
где HOST — узел, к которому устанавливается подключение, NAME — имя VRF.
Как видно, цель достигнута и сети связаны именно так, как надо.
Динамическая маршрутизация в рамках VRF
Рассмотрим топологию на рисунке 2. Задача сводится к организации динамической маршрутизации в каждом из VRF. Пусть в первом это будет протокол OSPF, во втором — EIGRP. Конфигурация маршрутизатора R1 тогда будет выглядеть следующим образом:
router ospf 1 vrf ONE
network 10.0.1.0 0.0.0.255 area 0
network 10.0.2.0 0.0.0.255 area 0
Видно, что достаточно указать, в каком VRF должен работать процесс OSPF, чтобы все заработало.
router eigrp 100
no auto-summary
address-family ipv4 vrf TWO
network 10.0.3.0 0.0.0.255
network 10.0.4.0 0.0.0.255
no auto-summary
autonomous-system 100
exit-address-family
С EIGRP все немного сложнее, но тоже интуитивно понятно.
Для маршрутизаторов R1 и R2 конфигурации выглядят следующим образом:
router ospf 1
log-adjacency-changes
network 10.0.1.0 0.0.0.255 area 0
network 172.16.1.0 0.0.0.255 area 2
!network 172.16.2.0 0.0.0.255 area 1 для R2
Для маршрутизаторов R3 и R4:
router eigrp 100
network 10.0.3.0 0.0.0.255
network 172.16.3.0 0.0.0.255
!network 172.16.4.0 0.0.0.255 для R4
no auto-summary
Для того, чтобы убедиться, что все работает, достаточно посмотреть на таблицы маршрутизации.
Routing Table: ONE
…
Gateway of last resort is not set
172.16.0.0/24 is subnetted, 2 subnets
O IA 172.16.1.0 [110/2] via 10.0.1.2, 00:38:58, FastEthernet0/0
O IA 172.16.2.0 [110/2] via 10.0.2.2, 00:39:00, FastEthernet0/1
10.0.0.0/24 is subnetted, 2 subnets
C 10.0.2.0 is directly connected, FastEthernet0/1
C 10.0.1.0 is directly connected, FastEthernet0/0
R1#show ip route vrf TWO
Routing Table: TWO
…
Gateway of last resort is not set
172.16.0.0/24 is subnetted, 2 subnets
D 172.16.4.0 [90/30720] via 10.0.4.2, 00:17:37, FastEthernet1/1
D 172.16.3.0 [90/30720] via 10.0.3.2, 00:17:50, FastEthernet1/0
10.0.0.0/24 is subnetted, 2 subnets
C 10.0.3.0 is directly connected, FastEthernet1/0
C 10.0.4.0 is directly connected, FastEthernet1/1
R2#show ip route
…
Gateway of last resort is not set
172.16.0.0/24 is subnetted, 2 subnets
C 172.16.1.0 is directly connected, FastEthernet0/1
O IA 172.16.2.0 [110/3] via 10.0.1.1, 00:39:37, FastEthernet0/0
10.0.0.0/24 is subnetted, 2 subnets
O 10.0.2.0 [110/2] via 10.0.1.1, 00:39:37, FastEthernet0/0
C 10.0.1.0 is directly connected, FastEthernet0/0
R4#show ip route
…
Gateway of last resort is not set
172.16.0.0/24 is subnetted, 2 subnets
D 172.16.4.0 [90/33280] via 10.0.3.1, 00:18:40, FastEthernet0/0
C 172.16.3.0 is directly connected, FastEthernet0/1
10.0.0.0/24 is subnetted, 2 subnets
C 10.0.3.0 is directly connected, FastEthernet0/0
D 10.0.4.0 [90/30720] via 10.0.3.1, 00:18:52, FastEthernet0/0
Заключение
В статье приведены команды, необходимые для функционирования маршрутизатора с несколькими таблицами маршрутизации. Кроме того, описана настройка основных IGP протоколов маршрутизации в рамках одного VRF.
Виртуальные сети Cisco VRF — Лемешко Евгений — LiveJournal
Еще в копилку полезная статья, опубликованная на ресурсе:cisco-lab.by Написано понятным и простым языком, поможет разобраться с VRF, для чего он нужен и собственно, на элементарном примере, как настраивается.Что такое виртуальная машина знают все. Каждый из нас, кто работает в сфере ИТ, как минимум слышал такое слово, большинство же, безусловно, работало или работает с ними. Кто-то использует их для тестирования приложений, кто-то для хостинга, кто-то для учебы и так далее, так как вариантов для использования масса.
Вот мы и задались вопросом: есть ли такие возможности в сети, и если есть, то как их использовать. То есть основный смысл заключается в том, возможно ли используя один комплект оборудования создать несколько независимых виртуальных сетей.
Зачем это нужно? По ряду причин:
— можно не изменять физическую связность, при этом создавать какую угодно логическую топологию;
— в каждой виртуальной сети можно настроить свой протокол и делать с ним лабораторные работы или проводить исследования;
— существенно увеличить количество логических маршрутизаторов, а соответственно и расширить возможности для построения сложных топологий;
— возможно создать для определенных приложений выделенную топологию, где это необходимо;
— при использовании виртуальной сети вместе с виртуальными машинами можно получить законченное полноценно виртуальное пространство;
— впишите свою причину, друзья 🙂
На самом деле можно перечислять очень долго, зачем это нужно. И у Вас, друзья, тоже найдется собственный список, как можно использовать виртуальную сеть. Потому мы перейдем к вопросу как создать виртуальную сеть.
Для того, чтобы создать сеть, необходимы каналы связи и активное сетевое оборудования, в частности маршрутизаторы. Для виртуальных сетей необходимы виртуальные каналы связи и виртуальные маршрутизаторы. Если с виртуальными каналами связи все более менее понятно: мы можем организовать их используя VLAN, чем мы активно пользовались в наших лабораторных работах. С виртуальными маршрутизаторами все не так очевидно, однако механизм тоже существует. Называется он VRF (Virtual Routing and Forwarding). Cisco активно позиционируют его как инструмент MPLS VPN, однако возможности его гораздо шире и не особо известны. Мы провели большую работу по изучению того, что может работать в виртуальной сети, какие протоколы и технологии. Далее последует серия статей об известных или не очень известных сетевых технологиях и протоколах в контексте виртуальных сетей. Пока же мы только объясним, что такое VRF и с чем его едят.
Виртуальный маршрутизатор, созданный при помощи VRF, обладает своей собственной таблицей маршрутизации, а также интерфейсами. Рассмотрим процесс создания и функционирования виртуальной сети на простеньком примере. Физическая топология сети:

Желаемая логическая топология:

Настроим маршрутизатор R1. R2 настраивается аналогичным образом, потому приводить его настройку мы не будем:
R1>ena
R1#conf t
R1(config)#ip vrf V1
R1(config-vrf)#descr Virtual Router 1
R1(config-vrf)#descr Virtual Router 1
R1(config-vrf)#ip vrf V3
R1(config-vrf)#descr Virtual Router 3
R1(config-vrf)#int fa 0/0.10
R1(config-subif)#enc dot 10
R1(config-subif)#ip vrf forwarding V1
R1(config-subif)#ip address 10.0.0.1 255.255.255.252
R1(config-subif)#int fa 0/0.11
R1(config-subif)#enc dot 11
R1(config-subif)#ip vrf forwarding V3
R1(config-subif)#ip address 10.0.0.6 255.255.255.252
R1(config-subif)#int fa 0/0.12
R1(config-subif)#enc dot 12
R1(config-subif)#ip vrf forwarding V3
R1(config-subif)#ip address 10.0.0.9 255.255.255.252
R1(config-subif)#int fa 0/0
R1(config-if)#no shut
R1(config-if)#int lo 0
R1(config-if)#ip vrf forwarding V1
R1(config-if)#ip address 10.0.1.1 255.255.255.0
Немного поясним настройку. Собственно создание виртуального маршрутизатора осуществляется командой «ip vrf ». Описание давать ему не обязательно, однако для упрощения понимания работы виртуальной сети лучше все-таки это сделать. Далее необходимо виртуальному маршрутизатору присвоить какие-нибудь интерфейсы. Это осуществляется командой «ip vrf forwarding ». Отметим, что привязывать интерфейс к виртуальному маршрутизатору необходимо до того, как настраивается IP-адрес. В противном случае адрес удалиться, о чем будет свидетельствовать характерное сообщение в консоли.
После того как мы создали виртуальные маршрутизаторы, мы можем посмотреть их список и их таблицы маршрутизации:



Согласитесь, друзья, никаких отличий в таблице маршрутизации виртуального маршрутизатора нет. Все нам привычно и знакомо.
Так как мы рассматриваем пока сам принцип функционирования виртуальной сети, то для создания полной связности мы настроим самое простое: статические маршруты. Пример их настройки для R1 (виртуальные маршрутизаторы V1 и V3):
R1(config)#ip route vrf V1 10.0.4.0 255.255.255.0 10.0.0.2
R1(config)#ip route vrf V1 10.0.0.4 255.255.255.252 10.0.0.2
R1(config)#ip route vrf V1 10.0.0.8 255.255.255.252 10.0.0.2
R1(config)#ip route vrf V3 10.0.1.0 255.255.255.0 10.0.0.5
R1(config)#ip route vrf V3 10.0.0.0 255.255.255.252 10.0.0.5
R1(config)#ip route vrf V3 10.0.4.0 255.255.255.0 10.0.0.10
Отличие в создание статических маршрутов заключается в указании виртуального маршрутизатора, которому принадлежит маршрут. Все остальное также, как и при настройке без виртуализации. Для R2 процесс настройки аналогичный, потому приводить его не будем. Проведем стандартные проверки: ping и traceroute:

Опять же, никаких особых отличий нет. Вся разница снова заключается в указании виртуального маршрутизатора, с которого мы будем осуществлять проверку доступности.
В следующей статье мы рассмотрим саму идеологию VRF.
Конфиги сетевого оборудования:
R1#sh run
Building configuration…
Current configuration : 1727 bytes
!
version 12.4
!
hostame R1
!
ip vrf V1
description Virtual Router 1
!
ip vrf V3
description Virtual Router 3
!
interface Loopback0
ip vrf forwarding V1
ip address 10.0.1.1 255.255.255.0
!
interface FastEthernet0/0
no ip address
duplex auto
speed auto
!
interface FastEthernet0/0.10
encapsulation dot1Q 10
ip vrf forwarding V1
ip address 10.0.0.1 255.255.255.252
!
interface FastEthernet0/0.11
encapsulation dot1Q 11
ip vrf forwarding V3
ip address 10.0.0.6 255.255.255.252
!
interface FastEthernet0/0.12
encapsulation dot1Q 12
ip vrf forwarding V3
ip address 10.0.0.9 255.255.255.252
!
ip route vrf V1 10.0.0.4 255.255.255.252 10.0.0.2
ip route vrf V1 10.0.0.8 255.255.255.252 10.0.0.2
ip route vrf V1 10.0.4.0 255.255.255.0 10.0.0.2
ip route vrf V3 10.0.0.0 255.255.255.252 10.0.0.5
ip route vrf V3 10.0.1.0 255.255.255.0 10.0.0.5
ip route vrf V3 10.0.4.0 255.255.255.0 10.0.0.10
!
end
R2#sh run
Building configuration…
Current configuration : 1717 bytes
!
version 12.4
!
hostname R2
!
ip vrf V2
!
ip vrf V4
!
interface Loopback0
ip vrf forwarding V4
ip address 10.0.4.1 255.255.255.0
!
interface FastEthernet0/0
no ip address
duplex auto
speed auto
!
interface FastEthernet0/0.10
encapsulation dot1Q 10
ip vrf forwarding V2
ip address 10.0.0.2 255.255.255.252
!
interface FastEthernet0/0.11
encapsulation dot1Q 11
ip vrf forwarding V2
ip address 10.0.0.5 255.255.255.252
!
interface FastEthernet0/0.12
encapsulation dot1Q 12
ip vrf forwarding V4
ip address 10.0.0.10 255.255.255.252
!
ip route vrf V2 10.0.0.8 255.255.255.252 10.0.0.6
ip route vrf V2 10.0.1.0 255.255.255.0 10.0.0.1
ip route vrf V2 10.0.4.0 255.255.255.0 10.0.0.6
ip route vrf V4 10.0.0.0 255.255.255.252 10.0.0.9
ip route vrf V4 10.0.0.4 255.255.255.252 10.0.0.9
ip route vrf V4 10.0.1.0 255.255.255.0 10.0.0.9
!
end
Sw1#sh run
Building configuration…
Current configuration : 1179 bytes
!
version 12.1
!
hostname Sw1
!
interface FastEthernet0/1
switchport trunk allowed vlan 10-12
switchport mode trunk
spanning-tree portfast trunk
!
interface FastEthernet0/2
switchport trunk allowed vlan 10-12
switchport mode trunk
spanning-tree portfast trunk
!
end
Описание, настройка и пример использования VRF на cisco
VRF – технология, позволяющая реализовывать на базе одного физического маршрутизатора иметь несколько виртуальных – каждого со своей независимой таблицей маршрутизации.
Преимуществом виртуальной маршрутизации является полная изоляция маршрутов как между двумя виртуальными маршрутизаторами, так и между виртуальным и реальным.
Чтобы было понятнее, приступим сразу к примеру.
Допустим, у нас есть большая сеть, где работает, скажем, EIGRP, и в этой сети есть маршрутизатор R1. Если мы зайдём на R1 и выполним там команду show ip route, то увидим большое количество маршрутов, пришедших со всех концов нашей сети. Теперь, предположим, что появился клиент, для которого надо сделать какие-то специфичные настройки. В первую очередь особую маршрутизацию, например, особый шлюз по умолчанию или ещё что-то, отдельный DHCP или отдельный NAT – тут то нам и приходит на помощь vrf.
Необходимо создать виртуальный маршрутизатор, выделить из всех интерфейсов те, которые будут к нему относиться и задать все необходимые настройки для него. Что характерно: никакие параметры, заданные для виртуального маршрутизатора не отразятся на работе реального.
Давайте перейдём к практике.
Посмотрим таблицу на нашем реальном маршрутизаторе:
Codes: C - connected, S - static, R - RIP, M - mobile, B - BGP
D - EIGRP, EX - EIGRP external, O - OSPF, IA - OSPF inter area
N1 - OSPF NSSA external type 1, N2 - OSPF NSSA external type 2
E1 - OSPF external type 1, E2 - OSPF external type 2
i - IS-IS, su - IS-IS summary, L1 - IS-IS level-1, L2 - IS-IS level-2
ia - IS-IS inter area, * - candidate default, U - per-user static route
o - ODR, P - periodic downloaded static route
Gateway of last resort is 212.192.128.177 to network 0.0.0.0
212.192.129.0/24 is variably subnetted, 7 subnets, 3 masks
D 212.192.129.144/28 [90/28416] via 212.192.128.186, 7w0d, FastEthernet0/0.100
D 212.192.129.128/28 [90/28416] via 212.192.128.186, 7w0d, FastEthernet0/0.100
D 212.192.129.160/27 [90/28416] via 212.192.128.186, 7w0d, FastEthernet0/0.100
D 212.192.129.192/27 [90/28416] via 212.192.128.190, 7w0d, FastEthernet0/0.100
S 212.192.129.224/27 is directly connected, FastEthernet0/0.606
D 212.192.129.0/26 [90/28416] via 212.192.128.186, 7w0d, FastEthernet0/0.100
…Много записей и нам совсем не хочется, чтобы наши действия повлияли на основную маршрутизацию.
Создаём виртуальный маршрутизатор:
configure terminal ip vrf MyRouter description VRF for nat from 10.0.0.0 to 55.55.55.55
Везде где можно написать description лучше его всегда писать.
Далее, выбираем, какие интерфейсы мы хотим отнести к этому vrf. В нашем примере у нас будет стоять задача брать трафик с интерфейса fa0/0.10 (ip 10.0.0.1), натить его и маршрутизировать через интерфейс fa0/0.55 (ip 55.55.55.55) так, чтобы это не влияло на остальные функции маршрутизатора.
interface fa0/0.10 encapsulation dot1q 10 ip vrf forwarding MyRouter ip address 10.0.0.1 255.255.255.0 ip nat inside interface fa0/0.55 encapsulation dot1q 55 ip vrf forwarding MyRouter ip address 55.55.55.55 255.255.255.0 ip nat outside
Интерфейсы созданы (в данном случае это сабинтерфейсы для работы с VLAN, но это не важно – можно использовать и обычные физические интерфейсы). Для каждого интерфейса мы указали, что трафик должен обрабатываться не по общим правилам а в соответствии с правилами MyRouter. Интерфейсы выходят из сферы влияния основной маршрутизации. Так, например, если мы сейчас напишем команду show ip route, то среди непосредственно подключенных сетей (те что с буковкой «C» в таблице маршрутизации) мы не увидим сетей 10.0.0.0/24 и 55.55.55.0/24. Зато теперь мы можем посмотреть, как выглядит таблица маршрутизации нашего виртуального роутера, для этого набираем команду:
show ip route vrf MyRouter
Вот её вывод:
Routing Table: MyRouter
Codes: C - connected, S - static, R - RIP, M - mobile, B - BGP
D - EIGRP, EX - EIGRP external, O - OSPF, IA - OSPF inter area
N1 - OSPF NSSA external type 1, N2 - OSPF NSSA external type 2
E1 - OSPF external type 1, E2 - OSPF external type 2
i - IS-IS, su - IS-IS summary, L1 - IS-IS level-1, L2 - IS-IS level-2
ia - IS-IS inter area, * - candidate default, U - per-user static route
o - ODR, P - periodic downloaded static route
Gateway of last resort is not set
10.0.0.0/24 is subnetted, 1 subnets
C 10.0.0.0 is directly connected, FastEthernet0/0.10
55.55.0.0/24 is subnetted, 1 subnets
C 55.55.55.0 is directly connected, FastEthernet0/0.55То есть, перед нами простая чистая таблица маршрутизации. Весь трафик, пришедший на fa0/0.10 и fa0/0.55 будет обрабатываться исходя только из одной этой таблицы – то есть общая таблица маршрутизации с кучей маршрутов приниматься во внимание не будет. Теперь вспомним CCNA и добавим статический маршрут по умолчанию, чтобы всё уходило в сеть через fa0/0.55, который у нас в примере будет внешним. При добавлении маршрута нам следует указать, что его надо добавить не в общую таблицу, а в vrf MyRouter:
ip route vrf MyRouter 0.0.0.0 0.0.0.0 55.55.55.56
где 55.55.55.56 – адрес следующего хопа. Подобным образом мы можем добавлять в эту таблицу произвольные статические и динамические маршруты.
Давайте добавим на наш виртуальный маршрутизатор DHCP и NAT. Пусть клиенты из внутренней сети получают адреса по DHCP а на выходе эти адреса транслируются в 55.55.55.55:
ip dhcp excluded-address 10.0.0.1 10.0.0.10 ! ip dhcp pool MyDHCP vrf MyRouter network 10.0.0.0 255.255.255.0 domain-name domain.ru dns-server 8.8.8.8 default-router 10.0.0.1 ! access list 101 permit ip 10.0.0.0 0.0.0.255 any ip nat inside source list 101 interface FastEthernet0/0.55 vrf MyRouter overload
На этом настройка завершена. Обратите внимание, что как в DHCP пуле, так и в NAT-е мы указываем, что всё это относится не к основному, а к виртуальному маршрутизатору (vrf MyRouter).
Два провайдера одновременно или Dual ISP with VRF на Cisco
Добрый день! На написание этого материала меня вдохновил HunterXXI в своей статье Два провайдера одновременно или Dual ISP with VRF на Cisco. Я заинтересовался, изучил вопрос и применил на практике. Хотел бы поделится своим опытом в реализации Dual ISP на Cisco с реальным использованием одновременно двух ISP и, даже, балансировкой нагрузки.
Демо схема:
Описание:
Все действия выполняются на Cisco 1921 IOS Version 15.5(3)M3 с установленным модулем EHWIC-4ESG.
- Порты GigabitEthernet0/0 и GigabitEthernet0/1 задействованы для подключения ISP.
- Порты GigabitEthernet0/0/0 и GigabitEthernet0/0/1 сконфигурированы в TRUNK и подключены к коммутаторам.
- Для работы с локальной сетью используются VLAN интерфейсы.
- В данной схеме предусматривается три локальных IP сети 192.168.100.0/24 для VLAN 100, 192.168.101.0/24 VLAN 101 и 192.168.102.0/24 VLAN 102.
- В данном примере VLAN 100 и 101 будут иметь связь между собой но 101 будет без доступа к Интернету, а VLAN 102 будет иметь выход только в интернет.
Так задумано что бы показать возможности импорта/экспорта между VRF.
Оставшиеся физические порты не задействованы, но Вам ничто не мешает их использовать по собственному усмотрению.Настройка Gi0/0/0 и Gi0/0/1
interface GigabitEthernet0/0/0
description TRUNK=>sw-access-1
switchport mode trunk
no ip address
end
interface GigabitEthernet0/0/1
description TRUNK=>sw-access-2
switchport mode trunk
no ip address
endКонфигурация VRF
Технология Cisco Express Forwarding (CEF) — должна быть включена для работы VRF.
Настройка VRF для ISP
ip vrf isp1
description ISP1
rd 65000:1
route-target export 65000:1
route-target import 65000:100
route-target import 65000:102
ip vrf isp2
description ISP2
rd 65000:2
route-target export 65000:2
route-target import 65000:100
route-target import 65000:102
Обратите внимание, что в конфигурации нет импорта 65000:101 который будет закреплен за VLAN 101. Таким образом виртуальные маршрутизаторы isp1 и isp2 не будут иметь маршрутов в сеть 192.168.101.0/24
Настройка VRF для VLAN
ip vrf 100
description VLAN_Desktop
rd 65000:100
route-target export 65000:100
route-target import 65000:1
route-target import 65000:2
route-target import 65000:101
ip vrf 101
description VLAN_Voice
rd 65000:101
route-target export 65000:101
route-target import 65000:100
ip vrf 102
description VLAN_Wireless
rd 65000:102
route-target export 65000:102
route-target import 65000:1
route-target import 65000:2
Снова обратите внимание на VRF 101, который не обменивается маршрутами c ISP но обменивается с VRF 100.
На своём опыте я убедился, что название VRF для ISP удобно использовать как isp1 и isp2, название VRF для VLAN должно соответствовать номеру VLAN, всё что идентифицирует VRF — description. Это связано с тем, что если, например, у Вас поменяется один из провайдеров то вся реконфигурация сведется к изменению IP адреса интерфейса и description-а.
Конфигурация интерфейсов
Применять команду ip vrf forwarding на интерфейсе нужно до назначения IP адреса. В противном случае IP адрес будет удалён и его придётся назначать заново.
WAN
interface GigabitEthernet0/0
description ISP1
ip vrf forwarding isp1
ip address 198.51.100.1 255.255.255.252
ip nat outside
interface GigabitEthernet0/1
description ISP2
ip vrf forwarding isp2
ip address 203.0.113.1 255.255.255.252
ip nat outside
LAN
interface Vlan100
description VLAN_Desktop
ip vrf forwarding 100
ip address 192.168.100.254 255.255.255.0
ip nat inside
interface Vlan101
description VLAN_Voice
ip vrf forwarding 101
ip address 192.168.101.254 255.255.255.0
ip nat inside
interface Vlan102
description VLAN_Wireless
ip vrf forwarding 102
ip address 192.168.102.254 255.255.255.0
ip nat inside
Не забудьте создать соответствующие VLAN-ы
vlan 100
name Desktop
exit
vlan 101
name Voice
exit
vlan 102
name Wireless
exit
show vlan-switch
VLAN Name Status Ports
---- -------------------------------- --------- -------------------------------
1 default active
100 Desktop active
101 Voice active
102 Wireless active
interface Vlan1
shutdownКонфигурация BGP
router bgp 65000
bgp log-neighbor-changes
address-family ipv4 vrf 100
redistribute connected
maximum-paths 2
exit-address-family
address-family ipv4 vrf 101
redistribute connected
exit-address-family
address-family ipv4 vrf 102
redistribute connected
maximum-paths 2
exit-address-family
address-family ipv4 vrf isp1
redistribute connected
redistribute static route-map BGP_Filter
default-information originate
exit-address-family
address-family ipv4 vrf isp2
redistribute connected
redistribute static route-map BGP_Filter
default-information originate
exit-address-family
Каждый из BGP address-family настраивается отдельно для VRF и перераспределяет подключенные маршруты (redistribute connected). У нас будет два маршрута по умолчанию, один через VRF isp1 и второй через isp2. Параметр maximum-paths 2 позволит импортировать в VRF 100 и 102 оба маршрута по умолчанию.
Это будет выглядеть так:
show ip route vrf 100
B* 0.0.0.0/0 [20/0] via 203.0.112.2 (isp2), 0d01h
[20/0] via 198.51.100.2 (isp1), 0d01hМаршрутизаторы Cisco автоматически балансируют трафик по маршрутам в одном направлении с одинаковой стоимостью.
В VRF isp1 и isp2 необходимо, помимо redistribute connected, разрешить redistribute static и default-information originate, что позволит передать шлюз по умолчанию в другие VRF. Вы можете заметить, что redistribute static делается через route-map BGP_Filter. Это происходит исключительно из соображений эстетического вида таблиц маршрутизации VRF определенных в локальную сеть, что бы маршруты к 8.8.8.8 и 80.80.80.80 не попадали в таблицы маршрутизации VRF 100 и 102.
Настройка маршрутизации
Приступим к настройке маршрутизации. Одной из особенностей работы с VRF, которая усложняет конфигурацию, является необходимость всё определять в конкретный VRF.
ip route vrf isp1 0.0.0.0 0.0.0.0 198.51.100.2 tag 100 track 100
ip route vrf isp2 0.0.0.0 0.0.0.0 203.0.112.2 tag 100 track 200- tag — поможет нам отфильтровать для передачи в локальные VRF только эти маршруты
- track — указывает какой объект отвечает за работоспособность маршрута
route-map BGP_Filter permit 10
description Fix BGP static redistribution
match tag 100Используя этот route-map и применяя его в VRF для ISP перераспределяться будут только маршруты с тэгом, а остальные останутся только внутри ISP VRF.
ip route vrf isp1 8.8.8.8 255.255.255.255 198.51.100.2
ip route vrf isp1 80.80.80.80 255.255.255.255 198.51.100.2
ip route vrf isp2 8.8.8.8 255.255.255.255 203.0.112.2
ip route vrf isp2 80.80.80.80 255.255.255.255 203.0.112.2Отдельные маршруты к хостам 8.8.8.8 и 80.80.80.80 необходимы для того, что когда сработает track и отключит шлюз по умолчанию у нас осталась возможность совершать проверку доступности этих адресов. Так как мы не присваиваем им тэг они не будут подпадать под route-map и перераспределяться.
Настройка NAT
Для работы NAT необходимо обозначить inside, outside интерфейсы. В качестве outside мы определяем интерфейсы в которые подключены ISP, командой ip nat outside. Все остальные интерфейсы, которые относятся к LAN обозначаем как inside командой ip nat inside.
Необходимо создать два route-map-а в которых определяются интерфейсы isp1 и isp2
route-map isp1 permit 10
match interface GigabitEthernet0/0
route-map isp2 permit 10
match interface GigabitEthernet0/1Правила NAT необходимо указывать для каждого VRF через каждый ISP. Так как в нашем условии Vlan 101 не имеет доступа к сети Интернет то правила для него указывать нет необходимости, а даже если их указать — работать не будет, потому что нет маршрутизации.
ip nat inside source route-map isp1 interface GigabitEthernet0/0 vrf 100 overload
ip nat inside source route-map isp2 interface GigabitEthernet0/1 vrf 100 overload
ip nat inside source route-map isp1 interface GigabitEthernet0/0 vrf 102 overload
ip nat inside source route-map isp2 interface GigabitEthernet0/1 vrf 102 overloadНемного теории NATУ Cisco есть много разновидностей NAT. В терминологии Cisco, то что мы используем называется Dynamic NAT with Overload или PAT.
Что нужно для того что бы NAT работал?
- Определить внутренний и внешний интерфейсы
- Указать, что мы хотим транслировать
- Указать, во что мы хотим транслировать
- Включить трансляцию
В простой конфигурации NAT достаточно создать access-list в котором определить локальную сеть и применить правило трансляции.
ip access-list extended NAT
permit ip 192.168.0.0 0.0.0.255 any
ip nat inside source list NAT interface GigabitEthernet0/0 overloadТаким образом мы указываем, что/во что и включаем трансляцию, то есть выполняем все необходимые требования.
Это настройка простой конфигурации, она очевидна и понятна без дополнительных подробностей.
Правило которое мы применяем в нашей конфигурации уже не так очевидно. Как мы помним, route-map isp1 определяет интерфейс GigabitEthernet0/0. Перефразируя команду получается нечто подобное
ip nat inside source GigabitEthernet0/0 interface GigabitEthernet0/0 overload in vrf 100Получается нужно транслировать трафик source которого GigabitEthernet0/0?
Для того что бы это понять необходимо погрузится в механизм прохождения пакета внутри маршрутизатора.
- Трафик который приходит на интерфейс который помечен как inside не подвергается трансляции. Он маркируется как возможно транслируемый.
- Следующим шагом обработки этого трафика является его маршрутизация согласно таблице маршрутизации или PBR.
- Если согласно таблице трафик попадает на интерфейс который отмечен как outside происходит его трансляция.
- Если трафик попадает на не outside интерфейс трансляции не происходит.
Ошибочно можно подумать, что можно делать route-map LAN match interface Vlan100. Применять этот как ip nat inside source route-map LAN и т.д.Спасибо IlyaPodkopaev NAT на Cisco. Часть 1Во избежание этой мысли нужно понять, что это правило трансляции срабатывает тогда, когда трафик уже находится на outside интерфейсе и match интерфейса где этого трафика уже нет ни к чему не приведет.
Настройка SLA
ip sla auto discovery
ip sla 10
icmp-echo 198.51.100.2
vrf isp1
frequency 5
ip sla schedule 10 life forever start-time now
ip sla 11
icmp-echo 8.8.8.8
vrf isp1
frequency 5
ip sla schedule 11 life forever start-time now
ip sla 12
icmp-echo 80.80.80.80
vrf isp1
frequency 5
ip sla schedule 12 life forever start-time now
ip sla 20
icmp-echo 203.0.112.2
vrf isp2
frequency 5
ip sla schedule 20 life forever start-time now
ip sla 21
icmp-echo 8.8.8.8
vrf isp2
frequency 5
ip sla schedule 21 life forever start-time now
ip sla 22
icmp-echo 80.80.80.80
vrf isp2
frequency 5
ip sla schedule 22 life forever start-time nowНичего особенного в конфигурации нет, проверятся доступность по ICMP узлов 8.8.8.8 80.80.80.80 и маршрутизаторов провайдера из каждого ISP VRF.
Настройка track
track 100 list boolean and
object 101
object 110
track 101 ip sla 10 reachability
delay down 20 up 180
track 102 ip sla 11 reachability
delay down 20 up 180
track 103 ip sla 12 reachability
delay down 20 up 180
track 110 list boolean or
object 102
object 103
track 200 list boolean and
object 201
object 210
track 201 ip sla 20 reachability
delay down 20 up 180
track 202 ip sla 21 reachability
delay down 20 up 180
track 203 ip sla 22 reachability
delay down 20 up 180
track 210 list boolean or
object 202
object 203
track 1000 stub-objectЛогика работы:
В таблице маршрутизации есть маршрут ip route vrf isp1 0.0.0.0 0.0.0.0 198.51.100.2 tag 100 track 100 который завязан на track 100.
- Если track 100 в состоянии UP то маршрут в таблице есть.
- Объект 100 это boolean and, что означает, что UP он будет считаться если все его объекты в состоянии UP.
- Если любой из объектов 100 DOWN то весть объект 100 будет DOWN.
- Он содержит объекты 101 и 110.
- Объект 101 соответствует SLA 10 — проверяет шлюз провайдера.
- Объект 110 объединяет 102 и 103 как boolean or, что означает, что он будет UP если хотя бы один из его объектов UP.
- Объекты 102 и 103 проверяют 8.8.8.8 и 80.80.80.80 соответственно, их нужно два для исключения ложных срабатываний.
Таким образом получается, что если отвечает шлюз по умолчанию провайдера и хотя бы один из внешних адресов то связь считается рабочей.
track 1000
track 1000 stub-object
default-state downЭтот объект умолчанию имеет состояние DOWN.
В данной конфигурации этот объект необходим для того, что бы принудительно отключить одного из ISP и не подключать его. Для этого track 1000 нужно добавить в объект 100 или 200. Исходя из boolean and, если один из объектов DOWN то весь объект считается DOWN.
Настройка EEM
EEM — Embedded Event Manager позволяет автоматизировать действия в соответствии с определенными событиями.
В нашем случае, когда один из ISP перестанет работать, он будет исключен из таблицы маршрутизации. Но правила трансляции NAT будут оставаться. Из-за этого, уже установленные пользовательские соединения зависнут до того момента пока трансляции NAT не очистится по тайм-ауту.
Для того, что бы ускорить этот процесс нам необходимо очистить таблицу NAT командой clear ip nat translation * и лучше всего сделать это автоматически.
event manager applet CLEANNAT-100
event track 100 state down
action 10 cli command "enable"
action 20 cli command "clean ip nat translation *"
event manager applet CLEANNAT-200
event track 200 state down
action 10 cli command "enable"
action 20 cli command "clean ip nat translation *"Если объекты 100 или 200 перейдут в состояние DOWN то будут выполнены команды action по порядку.
tips and tricks
Хочу отметить ещё несколько особенностей работы с VRF.
Например конфигурация NTP:
ntp server vrf isp1 132.163.4.103Из-за использования VRF любые сетевые операции нужно относить к виртуальному маршрутизатору, это связано с тем, что когда Вы настроите эту конфигурацию и выполните show ip route вы не увидите ни одной записи в таблице маршрутизации.
ping vrf isp1 8.8.8.8Будьте внимательны.
К преимуществам этой конфигурации я хотел бы отнести её гибкость. Можно с легкостью вывести один VLAN через одного ISP, а другой через второго.
К недостаткам, и это вопрос к уважаемой публике, когда отваливается один из ISP то команда clear ip nat translations * обрывает все соединения, включительно с работающим ISP. Как показала практика, в тех случаях когда отваливается провайдер — пользователи не замечают этот «обрыв» или он не является критичным.
Если кто-то знает как очищать таблицу трансляций частично — буду благодарен.
P.S>
Не забудьте запретить NAT трансляцию в приватные подсети.
ip access-list extended NO_NAT
deny ip any 192.168.0.0 0.0.255.255
deny ip any 172.16.0.0 0.15.255.255
deny ip any 10.0.0.0 0.255.255.255
permit ip any anyroute-map isp1 permit 10
match ip address NO_NAT
match interface GigabitEthernet0/0VRF — это… Что такое VRF?
VRF — Virtual Routing and Forwarding (VRF) is a technology used in computer networks that allows multiple instances of a routing table to co exist within the same router at the same time. Because the routing instances are independent, the same or… … Wikipedia
VRF — Die Abkürzung VRF steht für: Vogtland Regional Fernsehen, ein 1994 gegründeter Regionalsender, der im Vogtland über Kabel und terrestrisch zu empfangen ist Virtual Routing and Forwarding, eine Routing Technik in IP Netzen, siehe VRF Instanz Die… … Deutsch Wikipedia
VRF — Routage Voir « routage » sur le Wiktionnaire … Wikipédia en Français
VRF — VPN Routing and Forwarding (Computing » Networking) * Variable Refrigerant Flow (Governmental » Transportation) * Visiting Research Fellow (Governmental » NASA) * Visiting Research Fellow (Business » Positions) * Visiting Research Fellow… … Abbreviations dictionary
vrf.J. — verflossenen Jahres EN last year … Abkürzungen und Akronyme in der deutschsprachigen Presse Gebrauchtwagen
VRF — abbr. Vector Relational Format … Dictionary of abbreviations
VRF-Instanz — Eine VRF Instanz bezeichnet eine im Cisco IOS implementierte Funktion, die einen neuen virtuellen Router auf einem physischen Router anlegt. Die Abkürzung VRF steht dabei für Virtual Routing and Forwarding. VRF Instanzen werden im Layer 3 des OSI … Deutsch Wikipedia
VRF Instanz — Eine VRF Instanz bezeichnet eine im Cisco IOS implementierte Funktion, die einen neuen virtuellen Router auf einem physischen Router anlegt. Die Abkürzung VRF steht dabei für Virtual Routing and Forwarding. VRF Instanzen werden im Layer 3 des OSI … Deutsch Wikipedia
Vrf Instanz — Eine VRF Instanz bezeichnet eine im Cisco IOS implementierte Funktion, die einen neuen virtuellen Router auf einem physischen Router anlegt. Die Abkürzung VRF steht dabei für Virtual Routing and Forwarding. VRF Instanzen werden im Layer 3 des OSI … Deutsch Wikipedia
VRF (Variable Refrigerant Flow) — Система кондиционирования с переменным расходом хладагента. Состоит из одного наружного и нескольких внутренних блоков различного типа (настенные, напольные, канальные, кассетные). Внутренние блоки работают с переменной производительностью,… … Глоссарий терминов бытовой и компьютерной техники Samsung
VRF (Variable Refrigerant Flow) — Система кондиционирования с переменным расходом хладагента. Состоит из одного наружного и нескольких внутренних блоков различного типа (настенные, напольные, канальные, кассетные). Внутренние блоки работают с переменной производительностью,… … Глоссарий терминов бытовой и компьютерной техники Samsung
VRF — это… Что такое VRF?
VRF — Virtual Routing and Forwarding (VRF) is a technology used in computer networks that allows multiple instances of a routing table to co exist within the same router at the same time. Because the routing instances are independent, the same or… … Wikipedia
VRF — Die Abkürzung VRF steht für: Vogtland Regional Fernsehen, ein 1994 gegründeter Regionalsender, der im Vogtland über Kabel und terrestrisch zu empfangen ist Virtual Routing and Forwarding, eine Routing Technik in IP Netzen, siehe VRF Instanz Die… … Deutsch Wikipedia
VRF — Routage Voir « routage » sur le Wiktionnaire … Wikipédia en Français
VRF — VPN Routing and Forwarding (Computing » Networking) * Variable Refrigerant Flow (Governmental » Transportation) * Visiting Research Fellow (Governmental » NASA) * Visiting Research Fellow (Business » Positions) * Visiting Research Fellow… … Abbreviations dictionary
vrf.J. — verflossenen Jahres EN last year … Abkürzungen und Akronyme in der deutschsprachigen Presse Gebrauchtwagen
VRF — abbr. Vector Relational Format … Dictionary of abbreviations
VRF-Instanz — Eine VRF Instanz bezeichnet eine im Cisco IOS implementierte Funktion, die einen neuen virtuellen Router auf einem physischen Router anlegt. Die Abkürzung VRF steht dabei für Virtual Routing and Forwarding. VRF Instanzen werden im Layer 3 des OSI … Deutsch Wikipedia
VRF Instanz — Eine VRF Instanz bezeichnet eine im Cisco IOS implementierte Funktion, die einen neuen virtuellen Router auf einem physischen Router anlegt. Die Abkürzung VRF steht dabei für Virtual Routing and Forwarding. VRF Instanzen werden im Layer 3 des OSI … Deutsch Wikipedia
Vrf Instanz — Eine VRF Instanz bezeichnet eine im Cisco IOS implementierte Funktion, die einen neuen virtuellen Router auf einem physischen Router anlegt. Die Abkürzung VRF steht dabei für Virtual Routing and Forwarding. VRF Instanzen werden im Layer 3 des OSI … Deutsch Wikipedia
VRF (Variable Refrigerant Flow) — Система кондиционирования с переменным расходом хладагента. Состоит из одного наружного и нескольких внутренних блоков различного типа (настенные, напольные, канальные, кассетные). Внутренние блоки работают с переменной производительностью,… … Глоссарий терминов бытовой и компьютерной техники Samsung
VRF (Variable Refrigerant Flow) — Система кондиционирования с переменным расходом хладагента. Состоит из одного наружного и нескольких внутренних блоков различного типа (настенные, напольные, канальные, кассетные). Внутренние блоки работают с переменной производительностью,… … Глоссарий терминов бытовой и компьютерной техники Samsung
Сети для самых маленьких. Часть одиннадцатая. MPLS L3VPN
[Все выпуски]10. Сети для самых маленьких. Часть десятая. Базовый MPLS
9. Сети для самых маленьких. Часть девятая. Мультикаст
8.1 Сети для Самых Маленьких. Микровыпуск №3. IBGP
8. Сети для самых маленьких. Часть восьмая. BGP и IP SLA
7. Сети для самых маленьких. Часть седьмая. VPN
6. Сети для самых маленьких. Часть шестая. Динамическая маршрутизация
5. Сети для самых маленьких: Часть пятая. NAT и ACL
4. Сети для самых маленьких: Часть четвёртая. STP
3. Сети для самых маленьких: Часть третья. Статическая маршрутизация
2. Сети для самых маленьких. Часть вторая. Коммутация
1. Сети для самых маленьких. Часть первая. Подключение к оборудованию cisco
0. Сети для самых маленьких. Часть нулевая. Планирование
В прошлый раз мы не оставили камня на камне при разборе MPLS. И это, пожалуй, хорошо.
Но до сих пор только призрачно прорисовывается применение его в реальной жизни. И это плохо.
Этой статьёй начнём исправлять ситуацию. Вообще же читателя ждёт череда из трёх статей: L3VPN, L2VPN, Traffic Engineering, где мы постараемся в полной мере рассказать, для чего нужен MPLS на практике.
Итак, linkmeup — уже больше не аутсорсинг по поддержке хоть и крупной, но единственной компании, мы — провайдер. Можно даже сказать федеральный провайдер, потому что наша оптика ведёт во все концы страны. И наши многочисленные клиенты хотят уже не только высокоскоростной доступ в Интернет, они хотят VPN.
Сегодня разберёмся, что придётся сделать на нашей сети (на которой уже меж тем настроен MPLS), чтобы удовлетворить эти необузданные аппетиты.
Традиционное видео:
Как организовать взаимодействие двух отдалённых узлов в сети Интернет? Очень просто, если они имеют публичные адреса — IP для этого и был придуман. Они могут общаться напрямую. В любом случае, чтобы соединить две точки в Интернете, нужно два публичных адреса — по одному с каждой стороны. А если у нас адреса частные (10/8, 172.16/20, 192.168/16)?
Тогда они будут «натиться» с одной стороны, а потом «разначиваться» с другой стороны. А NAT — штука, скажу я вам, ой, какая неприятная.
Поэтому существует VPN. Virtual Private Network — это набор технологий и протоколов, который позволяет подключить что-то к вашей частной сети через чужую сеть, в частности, через Интернет.
Например, Томский филиал компании linkmeup можно подключить к головному офису в Москве с помощью VPN через Интернет, как мы и делали в выпуске про VPN.
То есть другие филиалы через VPN вы будете видеть так, как если бы они находились в соседней комнате и подключены вы к ним через шнурок, коммутатор или маршрутизатор. Соответственно и общаться узлы могут по своим приватным адресам, а не по публичным.
В этом случае ваши личные данные с частными адресами упаковываются в пакеты с публичными адресами и как в туннеле летят через Интернет.
Это называется клиентский VPN, потому что клиент сам озабочен его конфигурацией и поднятием. Единственный его посредник — Интернет.
Его мы разобрали в 7-м выпуске и о нём же в блоге linkmeup есть огромная статья нашего читателя — Вадима Семёнова.
Другой возможный вариант — провайдерский VPN. В этом случае провайдер предоставляет клиенту несколько точек подключения, а внутри своей сети строит каналы между ними.
От клиента тогда требуется только оплачивать провайдеру этот канал.
Провайдерский VPN, в отличие от клиентского позволяет обеспечить определённое качество услуг. Обычно при заключении договора подписывается SLA, где оговариваются уровень задержки, джиттера, процент потерь пакетов, максимальный период недоступности сервисов итд. И если в клиентском VPN вы можете только уповать на то, что в интернете сейчас всё спокойно, и ваши данные дойдут в полном порядке, то в провайдерском, вам есть с кого спросить.
Вот на провайдерском VPN мы в этот раз и сосредоточимся.
Речь пойдёт о VPN 3-го уровня — L3VPN, когда нам необходимо обеспечить маршрутизацию сетевого трафика. L2VPN — тема следующего выпуска.
Когда речь заходит о VPN, возникает вопрос изоляции трафика. Никто другой не должен его получать, а ваши частные адреса не должны появляться там, где им не положено — то есть в Интернете, в сети нашего провайдера и в VPN других клиентов.
Когда вы настраиваете GRE-туннель через Интернет (или OpenVPN, на ваш вкус), то ваши данные автоматически обособлены — никто не видит ваши частные адреса в Интернете, и трафик не попадёт в чужие руки (если не поднимать вопрос нацеленной атаки).
То есть существует некий туннель между двумя публичными адресами, который никак не связан ни с вашим провайдером, ни с другими транзитными туннелями. Два разных VPN — два совершенно разных туннеля — и по вашему туннелю течёт только ваши трафик.
Совсем иначе стоит вопрос в провайдерском VPN — одна и та же магистральная сеть должна переносить данные сотен клиентов. Как тут быть?
Нет, можно, конечно, и тут GRE, OpenVPN, L2TP и иже с ними, но тогда всё, чем будут заниматься инженеры эксплуатации — это настраивать туннели и лопатить миллионы строк конфигурации.
Но проблема глубже — вопрос организации такого универсального для всех канала вторичен: главное сейчас — как изолировать двух клиентов, подключенных к одному маршрутизатору? Если, например, оба используют сеть 10.0.0.0/8, как не позволить трафику маршрутизироваться между ними?
Здесь мы приходим к понятию VRF — Virtual Routing and Forwarding instance. Терминология тут не устоявшаяся: в Cisco — это VRF, в Huawei — VPN-instance, в Juniper — Routing Instance. Все названия имеют право на жизнь, но суть одна — виртуальный маршрутизатор. Это что-то вроде виртуальный машины в каком-нибудь VirtualBox — там на одном физическом сервере поднимается много виртуальных серверов, а здесь на одном физическом маршрутизаторе есть много виртуальных маршрутизаторов.
Каждый такой виртуальный маршуртизатор — это по сути отдельный VPN. Их таблицы маршрутизации, FIB, список интерфейсов и прочие параметры не пересекаются — они строго индивидуальны и изолированы. Ровно так же они обособлены и от самого физического маршрутизатора. Но как и в случае виртуальных серверов, между ними возможна коммуникация.
VRF — он строго локален для маршрутизатора — за его пределами VRF не существует. Соответственно VRF на одном маршрутизаторе никак не связан с VRF на другом.
Раз уж мы рассматриваем все примеры на оборудовании Cisco, то будем придерживаться их терминологии.
VRF Lite
Так называется создание провайдерского VPN без MPLS.
Вот, например, так можно настроить VPN в пределах одного маршрутизатора:
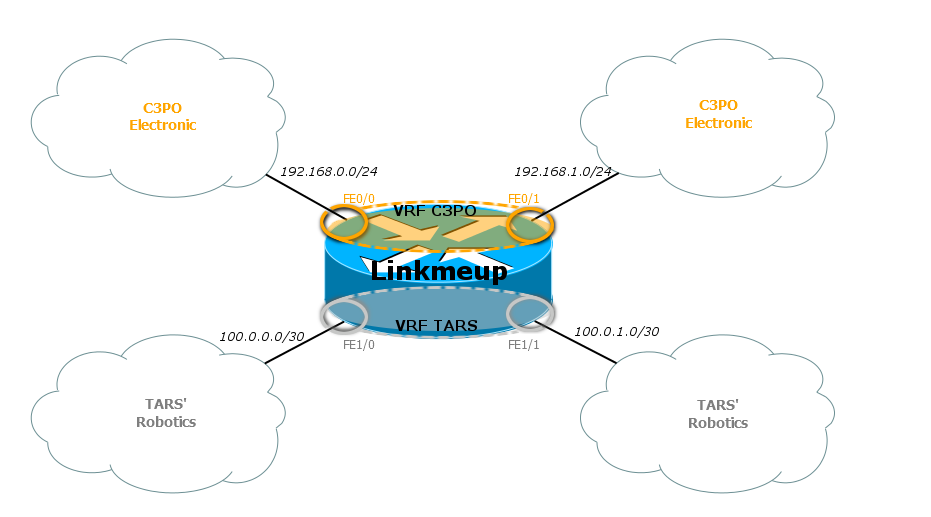
Тут у нас есть два клиента — TAR’s Robotics и C3PO Electronic.
Интерфейсы FE0/0 и FE0/1 принадлежат VPN C3PO Electronic, интерфейсы FE1/0 и FE1/1 — VPN TAR’s Robotics. Внутри одного VPN узлы общаются без проблем, между собой — уже никак.
Вот так выглядят их таблицы маршрутизации на провайдерском маршрутизаторе: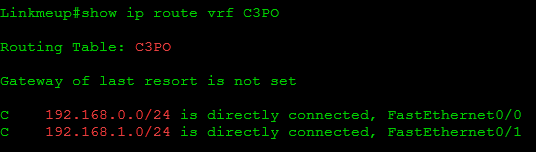
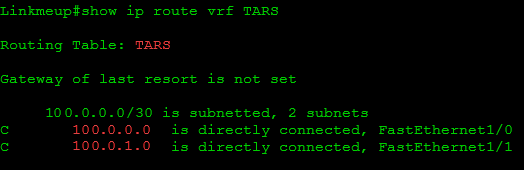
Маршруты C3PO Electronic не попадут в сети TARS’ Robotics и наоборот.
Клиентские интерфейсы здесь привязаны к конкретному VRF.
Один интерфейс не может быть членом двух VRF сразу или членом и VRF и глобальной таблицы маршрутизации.
Используя VRF Lite можно легко пробросить VPN между разными концами сети. Для этого нужно настроить одинаковые VRF на всех промежуточных узлах и правильно привязать их к интерфейсам:

То есть R1 и R2 будут общаться друг с другом через одну пару интерфейсов в глобальной таблице маршрутизации, через другую пару в VRF TARS’ Robotics и через третью в VRF C3PO Electronic. Разумеется, это могут быть сабинтерфейсы.
Аналогично между R2-R3.
Таким образом, получаются две виртуальные сети, которые друг с другом не пересекаются. Учитывая этот факт, в каждой такой сети нужно поднимать свой процесс IGP, чтобы обеспечить связность.
В данном случае будет один процесс для физического маршрутизатора, один для TARS’ Robotics, один для C3PO Electric. Соответственно, каждый из них будет сигнализироваться отдельно от других по своим собственным интерфейсам.
Если говорить о передаче данных, то пакет, придя от узла из сети TARS’s Robotics, сразу попадает в соответствующий VRF, потому что входной интерфейс R1 является его членом. Согласно FIB данного VRF он направляется на R2 через выходной интерфейс. На участке между R1 и R2 ходят самые обычные IP-пакеты, которые и не подозревают, что они принадлежат разным VPN. Вся разница только в том, что они идут по разным физическим интерфейсам, либо несут разный тег в заголовке 802.1q. R2 принимает этот пакет интерфейсом, который также член VRF TARS’s Robotics.
R2 варит пакет в нужном FIB и отправляет дальше, согласно IGP. И так до самого выхода пакета ну другой стороне сети.
Как узел определяет, что полученный пакет относится к определённому VPN? Очень просто: данный интерфейс привязан («прибинден») к конкретному VRF.
Как вы уже, вероятно, заметили, эти интерфейсы помечены на иллюстрации колечками соответствующего цвета.
Включим немного воображение:
Если пакет проходит через серое колечко, он переходит на серую сторону окрашивается в серый цвет. Далее он будет уже проверяться по серой таблице маршрутизации.
Аналогично, когда пакет проходит через золотое кольцо, он покрывается благородной позолотой и проверяется по золотой таблице маршрутизации.
Точно также выходные интерфейсы привязаны к VPN, и соответствующие таблицы маршрутизации знают, какие за ними сети находятся.
Учитывайте, что всё, что мы говорим о таблицах маршрутизации, касается и FIB — в каждом VPN свой собственный FIB.
Между маршрутизаторами пакеты не окрашены. Пакеты разных VPN не смешиваются, потому что идут либо по разных физическим интерфейсам, либо по одному, но имеют разные VLAN-теги (каждому VRF соответствует свой выходной саб-интерфейс).
Вот он простой и прозрачный VPN — для клиента сформирована самая что ни на есть частная сеть.
Но этот способ удобен, пока у вас 2-3 клиента и 2-3 маршрутизатора. Он совершенно не поддаётся масштабированию, потому что один новый VPN означает новый VRF на каждом узле, новые интерфейсы, новый пул линковых IP-адресов, новый процесс IGP/BGP.
А если точек подключения не 2-3, а 10, а если нужно ещё резервирование, а каково это поднимать IGP с клиентом и обслуживать его маршруты на каждом своём узле?
И тут мы подходим уже к MPLS VPN.
MPLS VPN позволяет избавиться от вот этих неприятных шагов:
1) Настройка VRF на каждом узле между точками подключения
2) Настройка отдельных интерфейсов для каждого VRF на каждом узле.
3) Настройка отдельных процессов IGP для каждого VRF на каждом узле.
4) Необходимость поддержки таблицы маршрутизации для каждого VRF на каждом узле.
Да как так-то?
Рассмотрим, что такое MPLS L3VPN на примере такой сети:
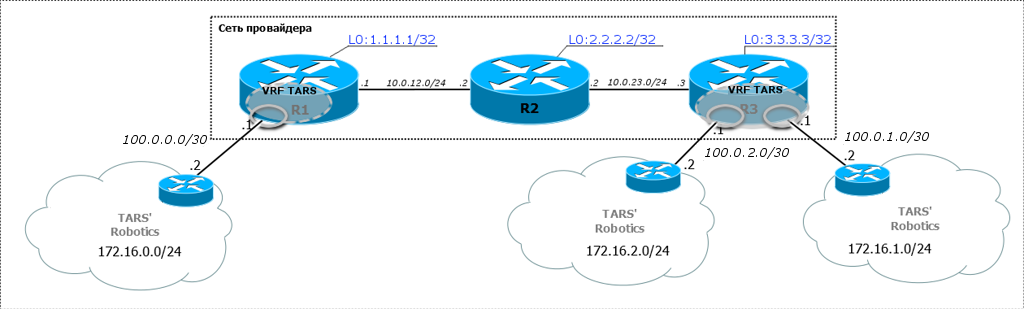
Итак, это три филиала нашего клиента TARS’ Robotics: головной офис в Москве и офисы в Новосибирске и Красноярске — весьма удалённые, чтобы дотянуть до них своё оптоволокно. А у нас туда уже есть каналы.
Центральное облако — это мы — linkmeup — провайдер, который предоставляет услугу L3VPN.
Вообще говоря, TARS Robotics как заказчику, совершенно без разницы, как мы организуем L3VPN — да пусть мы хоть на поезде возим их пакеты, лишь бы в SLA укладывались. Но в рамках данной статьи, конечно, внутри нашей сети работает MPLS.
Data Plane или передача пользовательских данных
Сначала надо бы сказать, что в MPLS VPN VRF создаётся только на тех маршрутизаторах, куда подключены клиентские сети. В нашем примере это R1 и R3. Любым промежуточным узлам не нужно ничего знать о VPN.
А между ними нужно как-то обеспечить изолированную передачу пакетов разных VPN.
Вот какой подход предлагает MPLS VPN: коммутация в пределах магистральной сети осуществляется, как мы описывали в предыдущей статье, по одной метке MPLS, а принадлежность конкретному VPN определяется другой — дополнительной меткой.
Подробнее:
1) Вот клиент отправляет пакет из сети 172.16.0.0/24 в сеть 172.16.1.0/24.
2) Пока он движется в пределах своего филиала (сеть клиента), он представляет из себя самый обычный пакет IP, в котором Source IP — 172.16.0.2, Destination IP — 172.16.1.2.
3) Сеть филиала знает, что добраться до 172.16.1.0/24 можно через Сеть провайдера.
До сих пор это самый обычный пакет, потому что стык идёт по чистому IP с частными адресами.
4) Дальше R1 (маршрутизатор провайдера), получает этот пакет, знает, что он принадлежит определённому VRF (интерфейс привязан к VRF TARS), проверяет таблицу маршрутизации этого VRF — в какой из филиалов отправить пакет — и инкапсулирует его в пакет MPLS.
Метка MPLS на этом пакете означает как раз его принадлежность определённому VPN. Это называется «Сервисная метка».
5) Далее наш маршрутизатор должен отправить пакет на R3 — за ним находится искомый офис клиента. Естественно, по MPLS. Для этого при выходе с R1 на него навешивается транспортная метка MPLS. То есть в этот момент на пакете две метки.
Продвижение пакета MPLS по облаку происходит ровно так, как было описано в выпуске про базовый MPLS. В частности на R2 заменяется транспортная метка — SWAP Label.
6) R3 в итоге получает пакет, отбрасывает транспортную метку, а по сервисной понимает, что тот принадлежит к VPN TARS’ Robotics.
7) Он снимает все заголовки MPLS и отправляет пакет в интерфейс таким, какой он пришёл на R1 изначально.
На диаграмме железо-углерод видно, как преображается пакет по ходу движения от ПК1 до ПК2:
Помните, чем хорош MPLS? Тем, что никому нет дела до того, что находится под меткой. Поэтому в пределах магистральной сети не важно, какие адресные пространства у клиента, то есть, какой IP-пакет кроется под заголовком MPLS.
Поскольку пакет коммутируется по меткам, а не маршрутизируется по IP-адресам — нет нужды поддерживать и таблицу маршрутизации VPN на промежуточных узлах.
То есть у нас получается такой удобный MPLS-туннель, который сигнализируется, как вы увидите дальше, автоматически.
Итак, в промежутке между R1 и R3 (то есть в облаке MPLS) ни у кого нет понимания, что такое VPN – пакеты VPN движутся по метками до пункта назначения, и только он уже должен волноваться, что с ними делать дальше. Это убирает необходимость поднимать VRF на каждом узле и, соответственно, поддерживать таблицу маршрутизации, FIB, список интерфейсов итд.
Учитывая, что весь дальнейший путь пакета определяется на первом MPLS-маршрутизаторе (R1), отпадает нужда и в индивидуальном протоколе маршрутизации в каждом VPN, хотя остаётся вопрос, как найти выходной маршрутизатор, на который мы ответим дальше.

Чтобы лучше понять, как передаётся трафик, нужно выяснить значение меток в пакете.
Роль меток MPLS
Если мы вернёмся к изначальной схеме с VRF-Lite, то проблема в том, что серый цвет IP-пакета (индикатор принадлежности к VPN TARS’ Robotics) существует только в пределах узла, при передаче его на другой эта информация переносится в тегах VLAN. И если мы откажемся от сабинтерфейсов на промежуточных узлах, начнётся каша. А сделать это нужно во благо всего хорошего.
Чтобы этого не произошло в сценарии с MPLS, Ingress LSR на пакет навешивает специальную метку MPLS — Сервисную — она идентификатор VPN. Egress LSR (последний маршрутизатор — R3) по этой метке понимает, что IP-пакет принадлежит VPN TARS’s Robotics и просматривает соответствующий FIB.
То есть очень похоже на VLAN, с той разницей, что только первый маршрутизатор должен об этом заботиться.
Но на основе сервисной метки пакет не может коммутироваться по MPLS-сети — если мы где-то её поменяем, то Egress LSR не сможет распознать, какому VPN она принадлежит.
И тут на выручку приходит стек меток, который мы так тщательно избегали в прошлом выпуске.
Сервисная метка оказывается внутренней — первой в стеке, а сверху на неё ещё навешивается транспортная.
То есть по сети MPLS пакет путешествует с двумя метками — верхней — транспортной и нижней — сервисной).
Для чего нужно две метки, почему нельзя обойтись одной сервисной? Пусть бы, например, одна метка на Ingress LSR задавал один VPN, другая — другой. Соответственно дальше по пути они бы тоже коммутировались как обычно, и Egress LSR точно знал бы какому VRF нужно передать пакет.
Вообще говоря, сделать так можно было бы, и это бы работало, но тогда в магистральной сети для каждого VPN был бы отдельный LSP. И если, например, у вас идёт пучок в 20 VPN с R1 на R3, то пришлось бы создавать 20 LSP. А это сложнее поддерживать, это перерасход меток, это лишняя нагрузка на транзитные LSR. Да и, строго говоря, это то, от чего мы тут пытаемся уйти.
Кроме того, для разных префиксов одного VPN могут быть разные метки — это ещё значительно увеличивает количество LSP.
Куда ведь проще создать один LSP, который будет туннелировать сразу все 20 VPN?
Транспортная метка
Таким образом, нам необходима транспортная метка. Она верхняя в стеке.
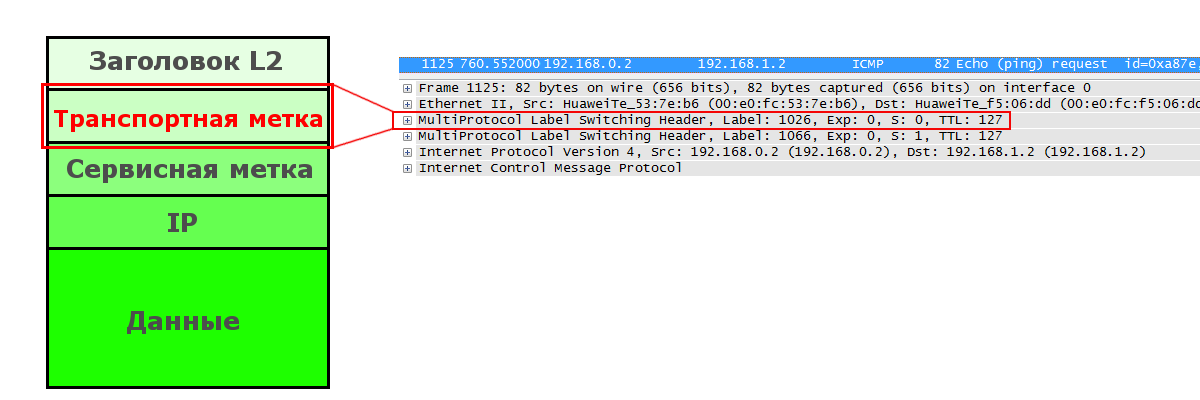
Она определяет LSP и меняется на каждом узле.
Она добавляется (PUSH) Ingress LSR и удаляется (POP) Egress LSR (или Penultimate LSR в случае PHP). На всех промежуточных узлах она меняется с одной на другую (SWAP).
Распространением транспортных меток занимаются протоколы LDP и RSVP-TE. Об этом мы тоже очень хорошо поговорили в прошлой статье и не будем останавливаться сейчас.
В целом транспортная метка нам мало интересна, поскольку всё и так уже понятно, за исключением одной детали — FEC.
FEC здесь уже не сеть назначения пакета (приватный адрес клиента), это адрес последнего LSR в сети MPLS, куда подключен клиент.
Это очень важно, потому что LSP не в курсе про всякие там VPN, соответственно ничего не знает о их приватных маршрутах/префиксах. Зато он хорошо знает адреса интерфейсов Loopback всех LSR. Так вот к какому именно LSR подключен данный префикс клиента, подскажет BGP — это и будет FEC для транспортной метки.
В нашем примере R1, опираясь на адрес назначения клиентского пакета, должен понять, что нужно выбрать тот LSP, который ведёт к R3.
Чуть позже мы ещё вернёмся к этому вопросу.
Сервисная метка
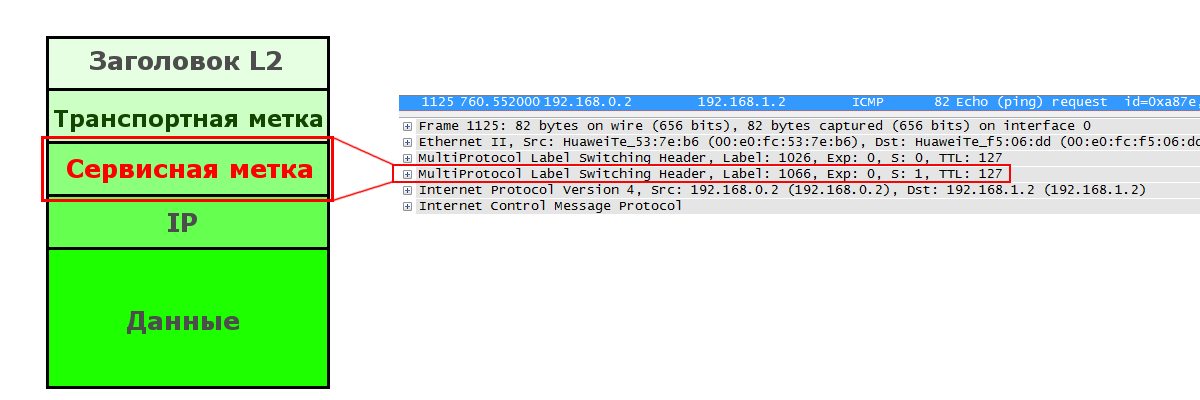
Нижняя метка в стеке — сервисная. Она является уникальным идентификатором префикса в конкретном VPN.
Она добавляется Ingress LSR и больше не меняется нигде до самого Egress LSR, который в итоге её снимает.
FEC для Сервисной метки — это префикс в VPN, или, грубо говоря, подсеть назначения изначального пакета. В примере ниже FEC – 192.168.1.0/24 для VRF C3PO и 172.16.1.0/24 для VRF TARS.
То есть Ingress LSR должен знать, какая метка выделена для этого VPN. Как это происходит — предмет дальнейших наших с вами исследований.
Вот так выглядит целиком процесс передачи пакетов в различных VPN’ах:
Обратите внимание, что для двух разных VPN отличаются сервисные метки – по ним выходной маршрутизатор узнаёт, в какой VRF передавать пакет.
А транспортные в данном случае одинаковые для пакетов обоих VRF, потому что они используют один LSP – R1↔R2↔R3.
Иллюстратор проекта — Анастасия Мецлер.
За помощь в подготовке статьи, спасибо JDima.
Оставайтесь на связи
Продолжение читайте тут: http://linkmeup.ru/blog/204.html
В силу ограничений длины топика в ЖЖ.